Dealing with Trees
tree.RmdGetting started
This tutorial discusses trees in rezonateR. In the first
tutorial vignette("import_save_basics"), we took a quick
glimpse at trees when discussing the node map, but now it’s time to dive
a bit deeper! And if you haven’t read the previous vignettes, as always,
that’s fine because each tutorial is self-contained. I won’t assume
you’ve read the bit about trees in
vignette("import_save_basics").
We will be using the same Santa Barbara Corpus annotation as before:
library(rezonateR)
path = system.file("extdata", "rez007_tree.Rdata", package = "rezonateR", mustWork = T)
rez007 = rez_load(path)
#> Loading rezrObj ...The file contains predicate-argument structures for the first fifth of the text or so. In practice, trees are often the most time-consuming data structure to process if you have annotated them throughout the whole text. Each tree is a predicate-argument structure with a tree as the root and all its arguments as leaves. In cases of IUs with more than one verb, multiple trees are created, one for each verb.
The structure of trees: A deeper look
There are three tree-related entities in Rezonator (and
rezonateR):
-
tree: Stores entire trees. -
treeEntry: The items that are linked together in trees. If you have not combined any tokens into tree entries inside Rezonator, then thetreeEntrys are correspond 1:1 to the tokens. This is the case if you are doing UD annotation, for example. If you have combined tokens, then those combined tokens will be entries. -
treeLink: The links between trees. Unlike regular links (such as those in trails or resonances)treeLinks can, and often are, annotated.
This section will examine each of these in detail.
Let’s first take a quick look at our treeDF:
head(rez007$treeDF$default)
#> # A tibble: 6 × 10
#> id doc name maxLe…¹ token…² docTo…³ token…⁴ docTo…⁵ text trans…⁶
#> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr> <chr>
#> 1 123586E4BA4… sbc0… Tree… 1 1 1 19 1029 (...… (...) …
#> 2 79D2B436E3F3 sbc0… Tree… 1 1 4 11 14 I sa… I said…
#> 3 36F1EB5B40F… sbc0… Tree… 1 1 4 11 14 I sa… I said…
#> 4 13085887E9F… sbc0… Tree… 1 1 15 6 20 (...… (...) …
#> 5 1B81715C6D0… sbc0… Tree… 1 1 21 13 33 (...… (...) …
#> 6 8A717C858193 sbc0… Tree… 1 1 34 4 37 (...… (...) …
#> # … with abbreviated variable names ¹maxLevel, ²tokenOrderFirst,
#> # ³docTokenSeqFirst, ⁴tokenOrderLast, ⁵docTokenSeqLast, ⁶transcriptThe main column of interest that you might not understand is
maxLevel. You can actually see maxLevel by
looking at Rezonator. The root of a tree has level 0,
whereas the next one down has a level of 1. Because of our
policy of marking only one predicate-arguments structure per tree, the
maxLevel always comes out as 1.
Now onto our treeEntrys:
head(rez007$treeEntryDF$default)
#> # A tibble: 6 × 15
#> id doc tree order sourc…¹ level token…² docTo…³ token…⁴ docTo…⁵ text
#> <chr> <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
#> 1 3419C1E… sbc0… 1235… 0 "" -1 1 1 1 1 (...)
#> 2 272B7E4… sbc0… 1235… 1 "" -1 2 2 2 2 God
#> 3 9403F19… sbc0… 1235… 2 "" -1 3 3 3 3 ,
#> 4 1FA8175… sbc0… 36F1… 0 "" -1 1 4 1 4 I
#> 5 E5564F0… sbc0… 1235… 3 "D98B0… 1 1 4 1 4 I
#> 6 87560FE… sbc0… 79D2… 0 "D4796… 1 1 4 1 4 I
#> # … with 4 more variables: transcript <chr>, parent <chr>, subtype <chr>,
#> # Relation <chr>, and abbreviated variable names ¹sourceLink,
#> # ²tokenOrderFirst, ³docTokenSeqFirst, ⁴tokenOrderLast, ⁵docTokenSeqLast
#> # ℹ Use `colnames()` to see all variable namesHere are some explanations of the unfamiliar entries:
-
order: Gives the order of the entry inside the tree, regardless of whether an entry has been used. -
level: Gives the level of the entry inside the tree. Unused entries get the level-1. If you want to get all the used entries of a particular tree, don’t forget to filter these away! -
sourceLink: The link that links the current entry to its parent. -
parent: The entry that thesourceLinkpoints to, i.e. the parent of the entry. Roots and unused entries do not have this.
The column Relation (and subtype) at the
end are automatically generated from treeLinkDF:
head(rez007$treeLinkDF)
#> # A tibble: 6 × 7
#> id doc source goal type subtype Relation
#> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 CBC2E1C85956 sbc007 84F24EF38C1F 2F22F7B57A855 treeLink tree Subj
#> 2 2807BDF6E02B1 sbc007 13F4ED1F2B04B A118F6B6F9AB treeLink tree NA
#> 3 152E54D7C23C5 sbc007 20596E3B9B865 2071B76B00FD0 treeLink tree Subj
#> 4 F92B516D0BE3 sbc007 2FECD465A75F1 3534C07CA8BAC treeLink tree Subj
#> 5 B3DC472623CA sbc007 37971169A2CD8 12E97EC7C488E treeLink tree NA
#> 6 229844F712123 sbc007 22C19DC0DED22 22791379CB56B treeLink tree SubjHere, source is the parent entry, goal is
the child entry, type is always treeLink,
subtype is always tree. Relation
is an annotation, manually annotated in Rezonator. Subjects are
annotated as Subj and others are left blank.
Linking things up: getAllTreeCorrespondences()
The function getAllTreeCorrespondences() adds a column
treeEntry to other rezrDFs like
chunkDF and trackDF to indicate corresponding
treeEntrys. The parameter entity determines
which entity you’re adding the information to. As always, if you set
entity to a ‘higher’ entity like track,
treeEntry is added to ‘lower’ entities like tokens and
chunks too. When there are multiple tree entries corresponding to
something, the first tree will take precedence. Let’s do this to
track:
rez007 = getAllTreeCorrespondences(rez007, entity = "track")
#> There is more than one tree entry match for the token 37EFCBECFD691. I will take the first match.
#> There is more than one tree entry match for the token 12D67756890C1. I will take the first match.
#> There is more than one tree entry match for the token 152560A5DE6AC. I will take the first match.
#> There is more than one tree entry match for the chunk 210FB26A315A. I will take the first match.
#> There is more than one tree entry match for the chunk 22273255D825D. I will take the first match.
head(rez007$tokenDF %>% select(id, text, treeEntry))
#> # A tibble: 6 × 3
#> id text treeEntry
#> <chr> <chr> <chr>
#> 1 31F282855E95E (...) ""
#> 2 363C1D373B2F7 God ""
#> 3 3628E4BD4CC05 , ""
#> 4 37EFCBECFD691 I "E5564F08F4F8"
#> 5 12D67756890C1 said "29A7D8B395830"
#> 6 936363B71D59 I "163E211526284"
head(rez007$chunkDF$refexpr %>% select(id, text, treeEntry))
#> # A tibble: 6 × 3
#> id text treeEntry
#> <chr> <chr> <chr>
#> 1 35E3E0AB6803A Stay up late ""
#> 2 1F6B5F0B3FF59 the purpose of getting up in the morning "5195D71DEA12"
#> 3 24FE2B219BD21 getting up in the morning ""
#> 4 158B579C1BA49 the morning ""
#> 5 2B6521E881365 all this other shit ""
#> 6 5B854594DD34 the way (...) they were feeling ""
head(rez007$trackDF$default %>% select(id, text, treeEntry))
#> # A tibble: 6 × 3
#> id text treeEntry
#> <chr> <chr> <chr>
#> 1 1096E4AFFFE65 I "E5564F08F4F8"
#> 2 92F20ACA5F06 I "163E211526284"
#> 3 7E5BB65072C was n't gon na do "35B1DC6EA25E5"
#> 4 1F74D2B049FA4 this "6FB5A1CE1B70"
#> 5 2485C4F740FC0 <0> "277C335C33462"
#> 6 1BF2260B4AB78 Stay up late ""Once this step is done, you can use the results to link up
information from the trees to other tables using
addFieldForeign() or rez_left_join(). In
anticpiation of the coming tutorial, let’s merge the
Relation field’s information into trackDF:
rez007 = rez007 %>%
addFieldForeign("track", "default", "treeEntry", "default", "treeEntry", "gramRelation", "Relation", fieldaccess = "foreign")
head(rez007$track$default %>% select(id, chain, text, treeEntry, gramRelation))
#> # A tibble: 6 × 5
#> id chain text treeEntry gramRelation
#> <chr> <chr> <chr> <chr> <chr>
#> 1 1096E4AFFFE65 278D0D84814BC I "E5564F08F4F8" NA
#> 2 92F20ACA5F06 278D0D84814BC I "163E211526284" Subj
#> 3 7E5BB65072C 2B670736C6823 was n't gon na do "35B1DC6EA25E5" NA
#> 4 1F74D2B049FA4 2A01379C5D049 this "6FB5A1CE1B70" NA
#> 5 2485C4F740FC0 278D0D84814BC <0> "277C335C33462" Subj
#> 6 1BF2260B4AB78 2A01379C5D049 Stay up late "" NAMerging chunks with tree entries
The current Rezonator interface only supports chunks within an intonation unit. However, there are often reasons to have chunks that span across intonation units. For example, people often start a new intonation unit within a noun phrase after a filler like uh…. Or we might want to treat an entire subordinate clause and its dependents as a single chunk.
There are two ways to merge chunks, but one way to do it is through tree entries. The steps are as follows:
- Create constituent chunks, one per each unit that the chunk spans so that, taken together, the chunks span the desired multiline chunk
- Create a
treeEntrythat contains all tokens in the merged chunk, and put the leaf in a tree. - Use the
mergeChunksWithTree()command inrezonateRto merge them.
Steps 1 and 2 were already done in Rezonator. Take the following example of a subordinate clause and its dependent clauses:
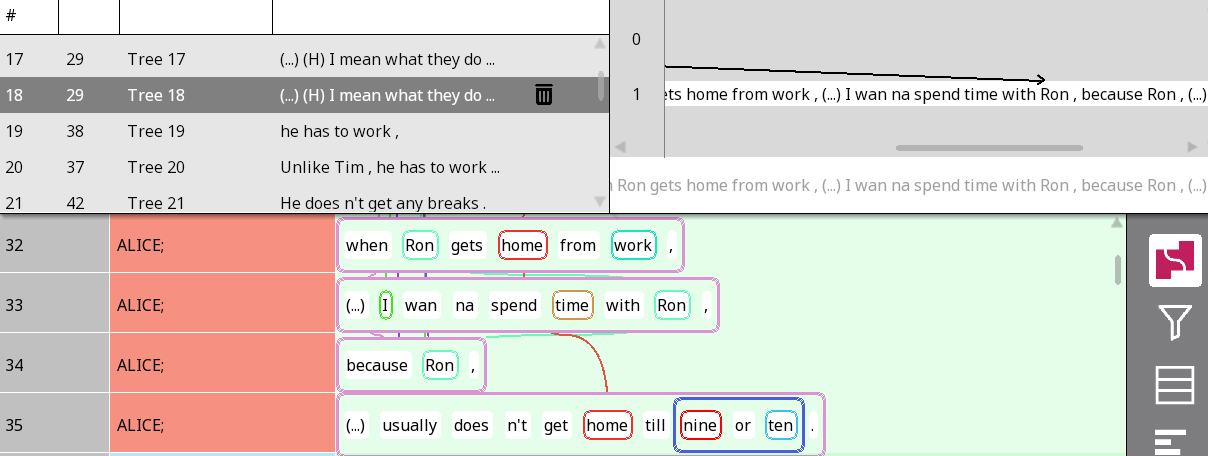
Figure 1: An image of the Rezonator interface with the four lines ‘when Ron gets home from work , (…) I wanna <0> spend time with Ron, because Ron, (…) usually does n’t get home till nine or ten’ each entered into a chunk in the same trail, and combined into a single treeEntry.
The function mergeChunksWithTree() helps you create the
desired multiline chunks. It has a few arguments, only the first of
which is obligatory;
-
rezrObj: TherezrObjto be changed. -
treeEntryDF: ThetreeEntryrezrDF, by defaulttreeEntry$default. -
addToTrack: Do you want to add the chunks to thetrackDFtoo? No by default. -
selectCond: A condition for selecting which chunk is going to provide the values of the tags of the entire chunk. If left blank, the first chunk will be chosen by default, which is the case here.
rez007 = mergeChunksWithTree(rez007)
#Relevant rows only
rez007$chunkDF$refexpr %>%
filter(combinedChunk != "") %>%
select(id, name, text, combinedChunk) #Showing only combined chunks and their members
#> # A tibble: 0 × 4
#> # … with 4 variables: id <chr>, name <chr>, text <chr>, combinedChunk <chr>
#> # ℹ Use `colnames()` to see all variable namesAfter you call this command, the merged chunks will be added to the
bottom of the correponding chunk rezrDF. Chunk
tags are taken from the first constituent chunk of each merger by
default; see the manual for setting custom conditions. There will in
addition be a column called combinedChunk that tells you
whether a chunk is a combined chunk, a member of a combined chunk, or
neither.
There are three possible types of values in
combinedChunk:
- If a chunk is a member of a multi-line chunk and supplies tag
information for the entire chunk, it has the
combinedChunkvalue|infomember-(ID of combined chunk). Usually this is the first chunk of the constituent chunks, unless you filled theselectCondargument ofmergeChunksWithTree(). - If a chunk is a member of a multi-line chunk and does not supply tag
information for the entire chunk, it has the
combinedChunkvalue|member-(ID of combined chunk). - The combined chunk is simply marked
combined.
If you didn’t set addToTrack = T, the function
mergeChunksToTrack has the same effect:
rez007 = mergedChunksToTrack(rez007, "default")Looking for family
In many applications, we may want to navigate tree using a chunk (or
token, track, or rez) as a starting point, such as finding the arguments
of a verb (its children), or the verb that a referential expression is
an argument of (its parent). Finding the parent is easy, because you can
just look up the parent column in treeEntryDF.
rezonateR provides some functions for finding siblings and
children as well.
addPositionAmongSiblings(): Finding the relative
position of an element among its siblings
One common thing we may want to do when investigating word order is to find the position of an element among its siblings. It has four :
-
chunkDF: ThechunkDFyou would like to find sibling position for. -
rezrObj: TherezrObjyou’re working with. -
treeEntryDFAddress: An address to thetreeEntryDF(seevignette("edit_tidyRez")for addresses). This can usually be left blank; by default it will be the union of all the tree entries. You only need to worry about this if you have multiple tree types. -
cond: Is there any condition for a chunk to be counted as a sibling? This can be useful for, for example, excluding adjuncts.
Here is how we would apply this function to referential expressions:
rez007$chunkDF$refexpr = addPositionAmongSiblings(rez007$chunkDF$refexpr, rez007)Advanced: Finding siblings and children of a chunk
For more advanced operations, there are several ways of finding the children and siblings of an entry or chunk:
-
getChildrenOfEntry(): Get the children of a tree entry. -
getChildrenOfChunk(): Get the children of a chunk (or token). -
getChildrenOfChunkIf(): Get the children of a chunk given a certain condition. -
getSiblingsOfEntry(): Get the siblings of a tree entry. -
getSiblingsOfChunk(): Get the siblings of a chunk (or token) -
getSiblingsOfChunkIf(): Get the siblings of a chunk given a certain condition.
Because rezrDFs discourage columns where each cell is a
vector, and you can have multiple siblings or children, it is not
encouraged to use these functions directly in rez_mutate()
or addField(), unless you can be confident that the result
is unique (e.g. if you are only looking for the subject of a clause, and
there can only be one subject in the data you’re working with).
The arguments of these functions are relatively straightforward: *
treeEntry: A treeEntry ID that you’re starting
from. * chunkID: A chunk ID that you’re starting from. *
treeEntryDF: A treeEntryDF from a
rezrObj. Must be a rezrDF, not a list;
combineLayers() can be used to combine multiple
rezrDFs. * chunkDF: A chunkDF
from a rezrObj, * cond: A condition using
columns from the chunkDF.
The only tricky thing about using these is the two
rezrDF arguments. They must be a single
rezrDF, not a list, and the chunkDF must
contain both parents and children (for child-related functions) and all
relevant siblings (for sibling-related functions). And of course, the
chunkDF must have a treeEntry column from
getAllTreeCorrespondences(). The functions
combineLayers(), combineChunks() or
combineTokenChunk() that we have discussed before in
vignette("import_save_basics") can be used to combine
multiple rezrDFs.
Here are two examples: First to find the siblings of the chunk
33EAD4C986974 mutual r respect, and then to find
the subject of the verb 388D9A04E5559 do
train:
siblings = getSiblingsOfChunk(chunkID = "33EAD4C986974",
chunkDF = rez007$chunkDF$refexpr,
treeEntryDF = rez007$treeEntryDF$default)
rez007$chunkDF$refexpr %>% filter(id %in% siblings)
#> # A tibble: 1 × 31
#> id doc name nest kind place text trans…¹ endNote order negPl…²
#> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 1FD903B61D7… sbc0… Chun… 2 "" "" what… what i… "" "" ""
#> # … with 20 more variables: corpusSeq <chr>, pSentOrder <chr>, POS_dft <chr>,
#> # tokenSeq <chr>, chunkType <chr>, turnOrder <chr>, tokenOrderFirst <dbl>,
#> # docTokenSeqFirst <dbl>, tokenOrderLast <dbl>, docTokenSeqLast <dbl>,
#> # layer <chr>, wordOrderFirst <dbl>, docWordSeqFirst <dbl>,
#> # wordOrderLast <dbl>, docWordSeqLast <dbl>, unitSeqFirst <dbl>,
#> # unitSeqLast <dbl>, treeEntry <chr>, combinedChunk <chr>, siblingPos <dbl>,
#> # and abbreviated variable names ¹transcript, ²negPlace
#> # ℹ Use `colnames()` to see all variable names
rez007 = rez007 %>%
addFieldForeign("chunk", "refexpr", "treeEntry", "default", "treeEntry", "gramRelation", "Relation", fieldaccess = "foreign") %>%
addFieldForeign("chunk", "verb", "treeEntry", "default", "treeEntry", "gramRelation", "Relation", fieldaccess = "foreign") %>%
addFieldForeign("token", "", "treeEntry", "default", "treeEntry", "gramRelation", "Relation", fieldaccess = "foreign")
getChildrenOfChunkIf(chunkID = "388D9A04E5559",
chunkDF = combineTokenChunk(rez007),
treeEntryDF = rez007$treeEntryDF$default,
cond = (gramRelation == "Subj"))
#> [1] "348254E9E5413"Speaking of tracks …
As usual, let’s not forget:
savePath = "rez007.Rdata"
rez_save(rez007, savePath)
#> Saving rezrObj ...