Importing Rezonator files, saving rezonateR objects, and basic data structure
import_save_basics.RmdHello! If you’re reading this tutorial, you’re probably wondering how exactly rezonateR works, how to import data into rezonateR and how to understand how the data is then structured internally. If this describes your situation, then this tutorial is for you!
If you are not yet familiar with what rezonateR does and want to see if this is the right tool for you, here are some pages that will work better for you:
e] ( https://rezonators.github.io/rezonateR/articles/sample_proj.html)
|
In this tutorial, you will learn about:
- The structure of Rezonator (
.rez) files, including a brief introduction to the structure of Rezonator’s internal JSON format - How to import your Rezonator files into
rezonateR - How to save and load your data as
rezrObjobjects, the central data structure ofrezonateR - Learn how the linguistic data is structured as a
nodeMapinside arezrObj - Learn how the data.frame
rezrDFinside arezrObjis structured, and some basic functions for manipulating these data frames (rezrDFs)
Rezonator file structure
Before we start talking about the details of importing, saving and
loading in rezonateR, we need to familiarise ourselves with
how Rezonator data is formatted first. In this section, we will:
Learn the different elements of a Rezonator file (such as tracks, trails, chunks and trees)
Install and import
rezonateRLearn, on a high level, how these elements are represented in node maps, the format behind
.rezfiles
Elements in a Rezonator file
To discuss the different elements of a Rezonator file, in this
tutorial we will be using a simple Rezonator file. This file contains a
minimal amount of annotation - just enough to explain the basic workings
of rezonateR without being bogged down in long loading
times that would result from a more extensively annotated files.
The data used in this example is from the text A Tree’s Life
(SBC007), a conversation between two sisters from the Santa Barbara
Corpus of Spoken American English. The first 162 lines have been
annotated and will be used in this tutorial; they deal with the topic of
one of the sisters’ roommates. (The data is also available through the
sbc007 object in the package itself, where a detailed
description of the annotations included may be found.)
Figure 1 shows an excerpt close to the beginning of the conversation in Rezonator:

Figure 1
In this file, each line is referred to as a unit, which in this context is an intonation unit (though lines may be sentences, clauses or other larger structures in other contexts.) Each unit consists of a series of tokens (‘words’) separate by spaces.
Tracks and trails
The file has been annotated for coreference chains, or trails. A trail consists of several mentions or referential expressions that refer to the same entity, each of which is individual called a track. They are connected by wavy lines in Rezonator. Here is one example:
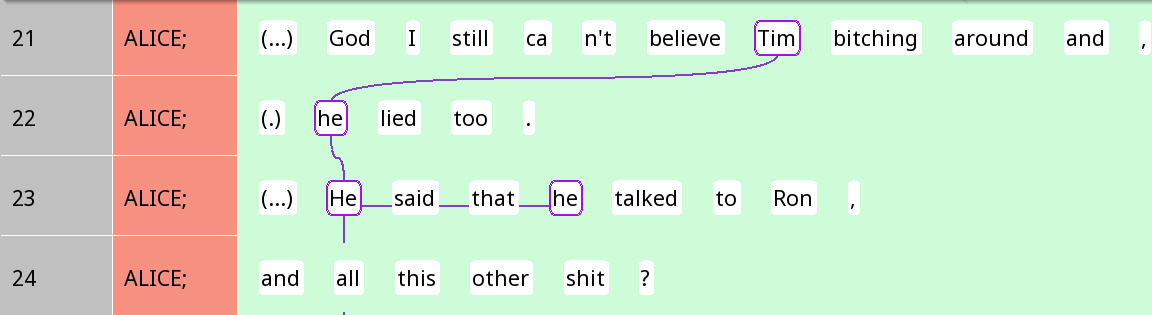
Figure 2
Here, the Tim and the two hes refer to the same person.
Zeroes
When there is a clause with an implicit participant that is not overtly expressed in the linguistic form, the symbol <0> is used to indicate the absence of such a form, and also included in a trail. Here is an example:

Figure 3
Notice that the two occurrences of I on Line 2 are linked together with a purple link, along with the zero on line 3.
Chunks
A ‘chunk’ in a Rezonator is a sequence of tokens within a unit, often a type of phrase such as a noun phrase. There are two types of chunks (elements represented by rectangles) in this file: Chunks that have been created as tracks which form part of a trail (mostly referential expressions), and verbal complexes, which are ‘blank chunks’, i.e. do not belong to any trail and appear with grey borders. The following figure shows some examples of these verbal chunks:
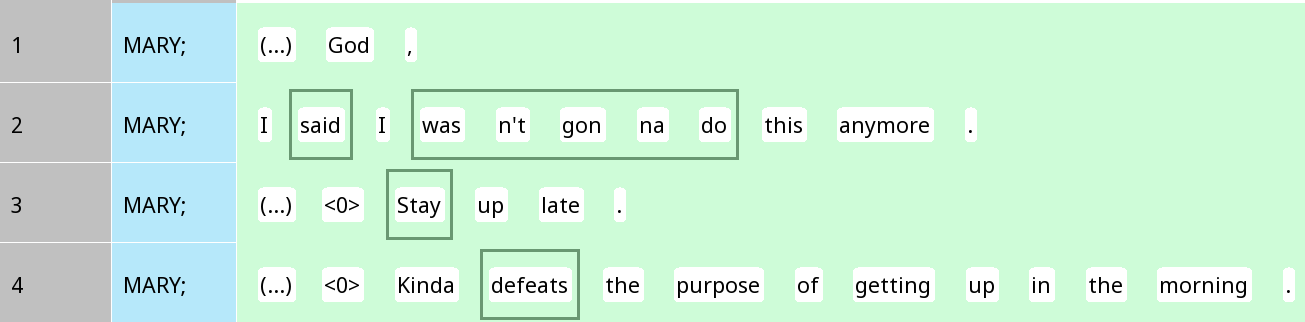
Figure 4
In this example, auxiliaries, negation and similar elements are placed inside these verbal complexes, as one can see from wasn’t gonna do.
Chunks have been annotated for two properties inside Rezonator.
chunkType is verb for verbs and left blank for
referential expressions, allowing us to distinguish between the two when
importing into rezonateR later. largerChunk is the larger
chunk to which a chunk belongs, which will be discussed later. These are
shown in Figure 5:

Figure 5
In this image, said is a verb and all the other chunks are referential expressions.
Trees
In Rezonator, trees are structures used to indicate relationships between words/chunks and other words/chunks. In ths file we’re working with, there are a number of two-layered trees that indicate argument structure of each verb. The root of each tree is the verb, and the arguments are the leaves. The following figure shows the argument structure of Line 4, with defeats as the root with three children: a zero subject, the object the purpose of getting up in the morning, and the adverb kinda:
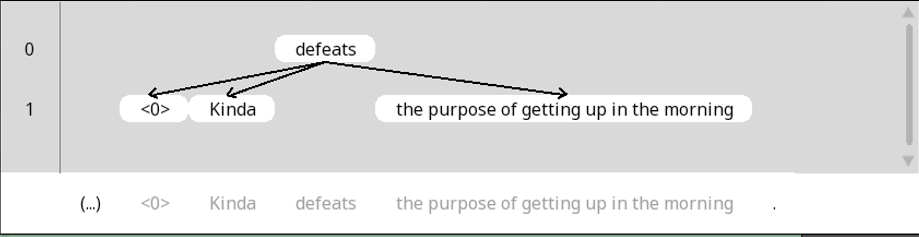
Figure 6
The links between different parts of a tree are also tagged with the field Relation. In this file, tree links are annotated as Relation = “Subject” when it indicates a subject-verb relation; otherwise Relation is left blank.
Installing rezonateR
In the sections below, you may benefit by following along with the code. To do this, use the following code:
install.packages("devtools")
library(devtools)
install_github("rezonators/rezonateR")Node maps: The secret life of Rezonator files
The .rez files produced by Rezonator are visualised
through the Rezonator interface, but they lead a secret double life!
Internally, they are represented by a structure called a node map. All
entities inside .rez files are represented as nodes, which
store information in the form of text, numbers and pointers to other
nodes. In this section, we will quickly explore the node map, which you
usually don’t need to deal with directly inside rezonateR,
but provides an important basis to understand how rezonateR
works.
To get an idea of what the node map looks like, let’s load a
.rez file. (You will never need to do this directly when
working in rezonateR, as the import function will handle it
for you; this is for demonstration purposes only.) We’ll extract the
node map from the .rez file after importing it into R, and
then store it in the variable rez007_nm. The R package
rjson converts the JSON format into a list format suitable
for access using R code.
library(rezonateR)
path = system.file("extdata", "sbc007.rez", package = "rezonateR", mustWork = T)
library(rjson)
getwd()
#> [1] "C:/Users/User/Documents/GitHub/rezonateR/vignettes"
rez007_json = rjson::fromJSON(file = path)
rez007_nm = rez007_json[["ROOT"]][[1]][["nodeMap"]]Let’s zero on to a single node. The simplest type of node is a token,
or a ‘word’ (this may be a morpheme or some other unit depending on the
language and data you’re working with.). Inside the Rezonator interface,
tokens are the basic unit that you may interact with. Let’s try the word
midnight. The word midnight that you see on the screen
has an ID of 28A862601A235, and that’s the key we access it
from the node map by. Let’s go ahead and examine some of the information
embeddded inside the node:
midnight = rez007_nm[["28A862601A235"]]
print(paste0("type: ", midnight$type))
#> [1] "type: token"
print(paste0("docTokenSeq: ", midnight$docTokenSeq))
#> [1] "docTokenSeq: 78"
print(paste0("unit: ", midnight$unit))
#> [1] "unit: 2D1B3667B6110"
print(paste0("place: ", midnight$place))
#> [1] "place: 6"
print(paste0("inEntryList: ", midnight$inEntryList))
#> [1] "inEntryList: 1A598AE39592B"
print(paste0("inChainsList: ", midnight$inChainsList))
#> [1] "inChainsList: 333DF666BC522"
print(paste0("inChunkList: ", midnight$inChunkList))
#> [1] "inChunkList: "
#tagMap:
print(sapply(midnight$tagMap, c))
#> kind place text transcript endNote order
#> "Word" "6" "midnight" "midnight" "" "6"
#> negPlace corpusSeq pSentOrder POS_dft tokenSeq chunkType
#> "1" "51219" "14" "NOUN" "86" ""
#> turnOrder largerChunk
#> "25" ""The type value indicates that we’re looking at a token;
other type values might be chunk,
stack, etc. docTokenSeq indicates the position
of the word within the document. unit is a pointer to the
node that contains the token’s unit. place gives the
position of the token within the unit.
The next three are lists of pointers to larger structures that may
contain the token. These ‘lists’ in .rez files are
represented by vectors, not lists, in R. inEntryList,
inChainsList and inChunkList give the entries,
chains and chunks in which ‘midnight’ are found. We will discuss entries
in the next section. A chain can be a Track chain, i.e. trail, or a Rez
chain, i.e. a resonance. In this case, ‘midnight’ was put in a trail,
albeit one that contains only itself (i.e. it is a singleton), which is
why you see a coloured box around the word, but no links emanating from
it (![]() ) .So
we do see a pointer to the track chain. It does not belong to any
chunks, i.e. the larger rectangles typically consisting of multiple
words.
) .So
we do see a pointer to the track chain. It does not belong to any
chunks, i.e. the larger rectangles typically consisting of multiple
words.
The tagMap of a specific node includes the tags that
were given when the raw file was first imported into Rezonator, as well
as tags that were created by Rezonator or manually added in Rezonator.
The tags in this specific example were all given during import; we will
see examples of these later.
Tokens and units
An entry is the intermediate layer between units and tokens. As a general rule, entries correspond one-to-one with tokens. This is a technicality that you will occasionally need to know when working in rezonateR.
A unit contains list of pointers referring to each individual entry
that is found within any unit of data (e.g. within an intonation unit).
This list can be accessed through the argument entryList.
To look up individual tokens from a unit, then, you will have to go to
individual entries’ nodes to look up the corresponding token. For
example, here is the entryList of the unit
2D1B3667B6110:
# entryList of unit 2D1B3667B6110:
print(rez007_nm[["2D1B3667B6110"]][["entryList"]])
#> [1] "24796648BFF31" "13E3DECAC86FF" "1D064F5FF52FD" "B2985F3730E0"
#> [5] "B6CC005C893A" "28B6FB7D926CC" "3794C89559C6D"To look up the first token in this unit, the word if, you need to look at the token value of the associated entry:
#Token corresponding to entry 24796648BFF31:
rez007_nm[["24796648BFF31"]][["token"]]
#> [1] "A27E39A69272"Let’s now verify that this token is indeed the word if:
#Text of the token A27E39A69272:
rez007_nm[["A27E39A69272"]]$tagMap$text
#> [1] "if"Chunks
A ‘chunk’ in a Rezonator is a sequence of tokens within a unit, often a type of phrase such as a noun phrase. A chunk is automatically created whenever you add a track or rez entry that spans more than one token, but not when you add a single-token track or rez entry. So, for example, in the following figure: midnight was not put inside a chunk, but the purpose of getting up in the morning was put in a chunk the moment it became part of a track chain.

Figure 7: A Rezonator screenshot with several chunks and two trails.
There are also chunks that do not belong to any chains, sometimes called blank chunks. In this document, blank chunks are used to mark verbal complexes in English, including verbs and auxiliaries, as well as any intervening adverbs, as you can see in the figure. When a nominal intervenes between the auxiliary and the verb, the auxiliary is excluded from the verb chunk.
The word Stay on line 3 belongs to a blank chunk containing
only Stay, and a chunk Stay up late in a track chain.
Let’s look at those two chunks. The ID for the token Stay is
1A0742C9033E5:
#Chunks that contain 1A0742C9033E5:
rez007_nm[["1A0742C9033E5"]]$inChunkList
#> [1] "35E3E0AB6803A"So the two chunks that contain Stay are
35E3E0AB6803A Stay up late and
15B9BB5D5086C Stay. 35E3E0AB6803A is
the larger chunk that belongs to a chain (note that the individual token
Stay 1A0742C9033E5 does not belong in the
chain):
#Chains that contain 35E3E0AB6803A:
rez007_nm[["35E3E0AB6803A"]]$inChainsList
#> [1] "2A01379C5D049"
#Chains that contain 1A0742C9033E5:
rez007_nm[["1A0742C9033E5"]]$inChainsList
#> list()A manually added field in this file, chunkType,
specifies the type of chunk that a certain chunk is. The field is blank
for mentions in track chains, but filled for verbs:
#chunkType of 35E3E0AB6803A:
rez007_nm[["35E3E0AB6803A"]]$tagMap$chunkType
#> [1] ""
#chunkType of 15B9BB5D5086C:
rez007_nm[["15B9BB5D5086C"]]$tagMap$chunkType
#> NULLThis point will be important later on when we import, as it will be used to separate chunks into layers.
Entries, links and chains
Rezonator currently has three data types that are termed ‘chains’. Each of them have specific names for their entries. They are:
-
A chain of track entities (i.e. mentions) is called a trail - i.e. a coreference chain containing mentions. For example, in the following screenshot contains a single trail, marked in blue, with three visible tracks: this, stay up late, and the <0>. Each track can be a token or chunk.

-
A chain of rez entities is a resonance - a rez entity is a specific instance of a word that is resonated somewhere else in the document, and a resonance is a collection of resonating tokens. The following screenshot has four resonances, each with two rezzes of the same word (usually, I, do, n’t). In this figure, each rez consists of a single token, but other annotations might allow for rezzes as chunks as well.
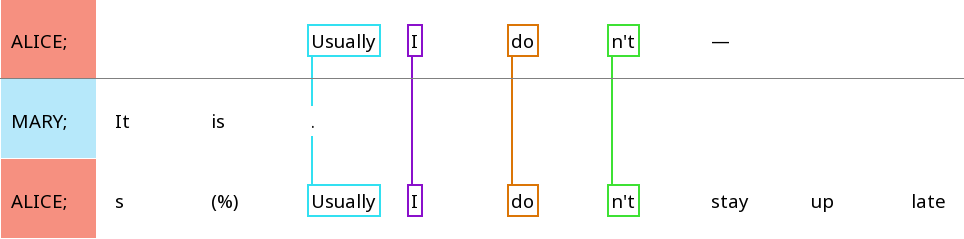
-
A chain of cards is a stack. A card corresponds to a unit, and a stack is basically a collection of units that make up some larger structure, for example a group of units inside a prosodic sentence or a turn. The following screenshot shows four stacks (in red, purple, beige and green, respectively). The first two and last stack have only one card, but the third beige stack has two cards, corresponding to the two units Her husband . and Gary Bighare ?.
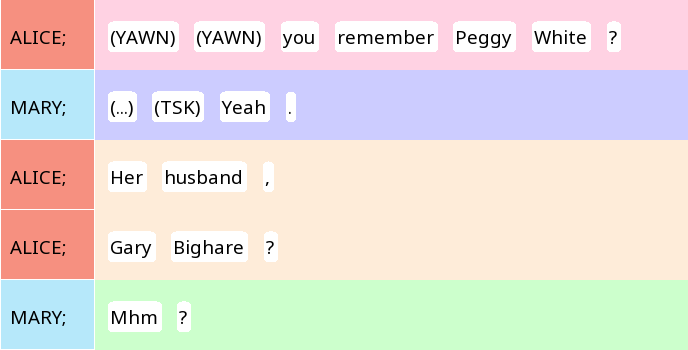
Figure 9
Let’s look at the track 1BF2260B4AB78, which corresponds to the chunk Stay up late 35E3E0AB6803A in Figure 8 above:
rez007_nm[["1BF2260B4AB78"]]$chain
#> [1] "2A01379C5D049"
rez007_nm[["1BF2260B4AB78"]]$token
#> [1] "35E3E0AB6803A"
rez007_nm[["1BF2260B4AB78"]]$goalLinkList
#> [1] "ED8C92307B42" "52452779949" "601CE9FAEBDB"Stay up late belongs to the chain, and corresponds to the
‘token’ 35E3E0AB6803A (this ‘token’ ID is actually a chunk - this is a
quirk of the .rez format that will be important to remember when working
in rezonateR) . goalLinkList is a list of links that starts
from this entry. Links live in a world of their own and are not
particularly important for working in rezonateR, so we can safely ignore
them for now.
To find out the member entries that a chain contains, you can look at
its setIDList.
rez007_nm[["2A01379C5D049"]]$setIDList
#> [1] "1BF2260B4AB78" "6B37B5A80F2A" "1F74D2B049FA4" "3098AB24A0FA6"
#> [5] "2E01153F693D3" "36B8918BB6E64"Entries and chains, like tokens (and units), have
tagMaps, and these generally correspond to tags generated
or manually added in Rezonator. Here’s the tagMap of the
track and trail we’ve seen. The track contains the tags
gapWords (number of words from the previous track) and
gapUnits (number of units from the previous track), as well
as counts for the number of tokens and characters inside the track. The
tag chainSize indicates the number of entries inside the
chain. These are all automatically generated by Rezonator and will be
covered in more detail when discussing coreference.
The tree map
Information related to trees reside in a sub-map of their own, separate from the other things we’ve been discussing so far. Here is an example of a tree from this file, containing the word ‘midnight’ we have discussed some time ago:
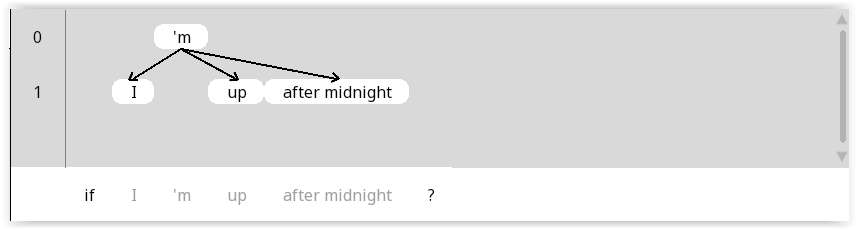
Figure 11: An image of a dependency tree in the Rezonator interface, with the root word ‘’m’, linked to the dependents I, up, after midnight.
There are three types of entities inside the tree map:
treeEntry, treeLink and tree:
- A
treeis, well, an individual tree. - A
treeEntryis a ‘node’ of a tree. It may contain one or multiple tokens - after midnight in our example, for example, contains two tokens, while the other two contain a single token, but each of them corresponds to only onetreeEntry, i.e. node in the tree. ThetreeEntryfrom which everything else branches out, in layer 0, is called the root. - A
treeLinkis a link between twotreeEntryentities
Unlike other links, treeLinks are important in
working with rezonateR!
The ID for the tree you see in the image is
10F850E894052. Let’s first see which tokens and
treeEntrys it consists of:
rez007_nm$treeMap[["10F850E894052"]]$tokenList
#> [1] "A27E39A69272" "3424455C58367" "35B9A7BEFAE4F" "13CB401695D9D"
#> [5] "176B4A79BFF4C" "28A862601A235" "2BFC755BC21BF"
rez007_nm$treeMap[["10F850E894052"]]$setIDList
#> [1] "85D2A496EF73" "31C3D31EB2618" "23BEEC722C8A0" "108A09B31C449"
#> [5] "31630BD346EC7" "2966966EBD888"Note that the above lists include other parts of the IU that were not actually included in the tree (but which appear on the Rezonator interface for you to add); you will often have to exclude them from analysis.
Now let’s examine one of the entries more closely.
31630BD346EC7 is the ID of after midnight, and we
can examine some of its attributes. The sourceLink
attribute gives the ID of the link to after midnight link from
’m, and tokenList gives the token IDs for the two
tokens after and midnight:
print(rez007_nm$treeMap[["31630BD346EC7"]]$sourceLink)
#> [1] "3FCE9430713C"
print(rez007_nm$treeMap[["31630BD346EC7"]]$tokenList)
#> [1] "176B4A79BFF4C" "28A862601A235"And to wrap it up, how about looking at the link? We can look at its
source (parent) and goal (child) treeEntry IDs, as well as
its tag Relation, which I’ve annotated as
Subj:
Importing Rezonator files and saving/loading rezonateR files
Now that we’ve studied the basic structure of a Rezonator file, it’s
time to actually start using rezonateR. In this section of
the tutorial, we will:
Learn how to import a
.rezfile into R as arezrObjSave and load the
rezrObjthat we createdLook at how the node map is represented in
rezrObjMost importantly, look at how the different data frames corresponding to nodes, called
rezrDFs, are structured
Importing Rezonator files
Let’s now actually import the file into rezonateR!
Obviously our first step is to import the package:
The import function is importRez(). When importing,
there are two important settings you will need to set. We will store the
values of these settings in variables before importing. The first one is
layerRegex:
layerRegex = list(chunk = list(field = "chunkType",
regex = c("verb"),
names = c("verb", "refexpr")))layerRegex allows you to separate chunks, tracks, rezes
and trees as well as associated entities such as trails and
treeEntrys into layers. (At the moment, it is not
technically possible for there to be stack layers, so this has not ye
been implemented for stacks.) Each layer will receive a separate data
frame.
In this file, we have two types of chunks: verbs and (largely)
referential expressions. Verbs are annotated with the
chunkType value ‘verb’, and referential expressions are
unannotated. In order to tell this to rezonateR, we need to
set pass a list to layerRegex. Permissible keys to this list include
chunk, track, rez,
tree; you can’t use other keywords (such as ‘trail’).
Each of these entries is another list with three values:
field, regex and names. The
element field specifies the name of the field that will
determine layer status (usually a dedicated field for determining the
layer, which in this case is chunkType). The element
regex specifies a list of regular expressions which, if
matched in the field specified by field, will put an entity
in a certain layer. The element names specifies the layer
names; when it has one more item than the regex list (in this case the
extra item is "refexpr"), then that layer is for items that
do not match any of the regexes.
If you do not assign layers to any of chunk, track, rez and
tree, everything will be placed in a layer called
default. In our case, track,
rez and tree (and their related entities, such
as treeEntry or resonance) are all put in a
layer called default. We will see how this works later
on.
The other setting is concatFields:
concatFields = c("text", "transcript")When we are just looking at nodeMaps, we often feel lost
because many nodes do not have any semblance of text on them. This is
undesirable when we are doing analysis using data imported into
rezonateR. In order to fix this, we can concatenate the
text or transript fields of the tokens associated with each node, and
this concatenated text will then be stored in the data frames that make
up a rezonateR object. These fields must be specified as a
vector passed to concatFields.
Here is the import function, using the settings from above. If you’re following on in R, do note that this takes long to run! The tree-related steps should, in particular, take extra time to process.
rez007 = importRez(path,
layerRegex = layerRegex,
concatFields = concatFields)
#> Import starting - please be patient ...
#> Creating node maps ...
#> Creating rezrDFs ...
#> Adding foreign fields to rezrDFs and sorting (this is the slowest step) ...
#> >Adding to unit entry DF ...
#> >Adding to unit DF ...
#> >Adding to chunk DF ...
#> >Adding to track DFs ...
#> >Adding to track DFs ...
#> >Adding to tree DFs ...
#> Splitting rezrDFs into layers ...
#> A few finishing touches ...
#> Done!Saving and loading rezonateR objects
The variable rez007 belongs to the class
rezrObj. To save the imported rezrObj
(something you will definitely want to do - nobody wants to import
again!), use the function rez_save(). To load it again, use
the function rez_load(). Both functions are quite easy:
rez_save() simply requires a rezrObj and a
save path, and rez_load() only a path to load from.
savePath = "rez007.Rdata"
rez_save(rez007, savePath)
#> Saving rezrObj ...
rez007 = rez_load(savePath)
#> Loading rezrObj ...A rezrObj consists of two components: a
nodeMap and a bunch of rezrDFs. Let’s look at
the nodeMap object first.
Meeting our nodeMap again
If you felt a bit lost when we were exploring .rez files
before, here’s some good news: nodeMaps in
rezonateR are slightly easier to navigate than the node map
in .rez files (phew)! The only major difference is that in
rezonateR nodeMaps, every item type belongs to
its own list. So the nodes in rez007’s nodeMap
are organised into these categories:
names(rez007$nodeMap)
#> [1] "entry" "token" "unit" "link" "card" "trail"
#> [7] "chunk" "track" "rez" "stack" "resonance" "doc"
#> [13] "corpus" "treeEntry" "treeLink" "tree"From nodeMap to rezrDF
The rezrDF is the soul of rezonateR.
rezrDFs are similar to each individual entity list in the
rezonateR nodeMap. However, instead of a list (dictionary)
representation, rezrDFs are data frames, with each row
being a node, and each column being its attributes.
There are a few ways in which columns are not identical to node attributes:
- While nodes in the
nodeMapare named using IDs, theidcolumn gives the ID of each node. -
tagMaps are ‘flattened’ (i.e. each tag its own column); thus there is no longer atagMapobject inrezrDFs: only the attribute-value pairs within it are retained. - Some attributes that are Rezonator-internal (e.g. focused on
visualisation in Rezonator) and not useful for data analysis are
discarded; you can always view them in the
nodeMapif you really want to. - List attributes are eliminated. (We will elaborate on this later.)
Each entity type in a rezrObj (token, track, trail,
etc.) has a corresponding rezrDF or set of rezrDFs
(tokenDF, trackDF, trailDF, etc.)
that is directly accessed from the rezrObj. For example, to
access the rezrDF corresponding to tokens, you would use
rez007$tokenDF. Other than nodeMap, all the
top-level entries of a rezrObj are rezrDFs:
names(rez007)
#> [1] "nodeMap" "cardDF" "chunkDF" "docDF" "entryDF"
#> [6] "linkDF" "mergedDF" "resonanceDF" "rezDF" "stackDF"
#> [11] "tokenDF" "trackDF" "trailDF" "treeDF" "treeEntryDF"
#> [16] "treeLinkDF" "unitDF"Here is the beginning of the tokenDF. Notice the
id column at the beginning, and the tags all getting their
own columns:
head(rez007$tokenDF)
#> # A tibble: 6 × 19
#> id doc unit docTo…¹ token…² kind place text trans…³ endNote order
#> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 31F282855… sbc0… 2AD1… 1 1 Pause "" (...) (...) "" 1
#> 2 363C1D373… sbc0… 2AD1… 2 2 Word "1" God God "" 2
#> 3 3628E4BD4… sbc0… 2AD1… 3 3 EndN… "" , , "conti… 3
#> 4 37EFCBECF… sbc0… BDD7… 4 1 Word "1" I I "" 1
#> 5 12D677568… sbc0… BDD7… 5 2 Word "2" said said "" 2
#> 6 936363B71… sbc0… BDD7… 6 3 Word "3" I I "" 3
#> # … with 8 more variables: negPlace <chr>, corpusSeq <chr>, pSentOrder <chr>,
#> # POS_dft <chr>, tokenSeq <chr>, chunkType <chr>, turnOrder <chr>,
#> # largerChunk <chr>, and abbreviated variable names ¹docTokenSeq,
#> # ²tokenOrder, ³transcript
#> # ℹ Use `colnames()` to see all variable namesLayers of rezDFs
For entity types with more than one layer, such as chunk or trail,
there is a list of rezrDFs instead of a single
rezrDF. For example, rez007$chunkDF contains
two rezrDFs. Note that there is a column layer
that contains the name of the layer, which will be identical across all
rows in a rezrDF:
head(rez007$chunkDF$refexpr)
#> # A tibble: 6 × 23
#> id doc name nest kind place text trans…¹ endNote order negPl…²
#> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 35E3E0AB680… sbc0… Chun… 2 "" "" Stay… Stay u… "" "" ""
#> 2 1F6B5F0B3FF… sbc0… Chun… 3 "" "" the … the pu… "" "" ""
#> 3 24FE2B219BD… sbc0… Chun… 2 "" "" gett… gettin… "" "" ""
#> 4 158B579C1BA… sbc0… Chun… 1 "" "" the … the mo… "" "" ""
#> 5 2F857247FD9… sbc0… Chun… 1 "" "" a ha… a hard… "" "" ""
#> 6 2B6521E8813… sbc0… Chun… 1 "" "" all … all th… "" "" ""
#> # … with 12 more variables: corpusSeq <chr>, pSentOrder <chr>, POS_dft <chr>,
#> # tokenSeq <chr>, chunkType <chr>, turnOrder <chr>, largerChunk <chr>,
#> # tokenOrderFirst <dbl>, docTokenSeqFirst <dbl>, tokenOrderLast <dbl>,
#> # docTokenSeqLast <dbl>, layer <chr>, and abbreviated variable names
#> # ¹transcript, ²negPlace
#> # ℹ Use `colnames()` to see all variable names
head(rez007$chunkDF$verb)
#> # A tibble: 6 × 23
#> id doc name nest kind place text trans…¹ endNote order negPl…²
#> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 210FB26A315A sbc0… Chun… 1 "" "" said said "" "" ""
#> 2 744AD104FE64 sbc0… Chun… 1 "" "" was … was n'… "" "" ""
#> 3 1A14BB68EDA… sbc0… Chun… 1 "" "" defe… defeats "" "" ""
#> 4 2CCD5F5A950… sbc0… Chun… 1 "" "" know know "" "" ""
#> 5 1F1135429F3… sbc0… Chun… 1 "" "" 's 's "" "" ""
#> 6 30F18BABDB8… sbc0… Chun… 1 "" "" do n… do n't] "" "" ""
#> # … with 12 more variables: corpusSeq <chr>, pSentOrder <chr>, POS_dft <chr>,
#> # tokenSeq <chr>, chunkType <chr>, turnOrder <chr>, largerChunk <chr>,
#> # tokenOrderFirst <dbl>, docTokenSeqFirst <dbl>, tokenOrderLast <dbl>,
#> # docTokenSeqLast <dbl>, layer <chr>, and abbreviated variable names
#> # ¹transcript, ²negPlace
#> # ℹ Use `colnames()` to see all variable namesMeanwhile, rez007$trailDF contains only one,
default:
head(rez007$trailDF$default)
#> # A tibble: 6 × 6
#> id doc chainCreateSeq name chain…¹ layer
#> <chr> <chr> <dbl> <chr> <dbl> <chr>
#> 1 2053E98E98EDE sbc007 10 the way they were feeling 2 defa…
#> 2 2DFABF7A78227 sbc007 68 right now 1 defa…
#> 3 13B30F106D8DF sbc007 27 The two couples 10 defa…
#> 4 21E91EA9BEFE2 sbc007 49 ànything positive about Tim… 1 defa…
#> 5 14CE0A33F22EB sbc007 71 the thing that really scare… 3 defa…
#> 6 4D1295B2824B sbc007 39 our parents 1 defa…
#> # … with abbreviated variable name ¹chainSizeWhen you have multiple layers, in many cases you will need to combine
information from all layers to perform certain actions in
rezonateR. There are functions to do this conveniently.
combineLayers() combines all rezrDFs of a
certain entity type. To use it, simply specify the rezrObj
and the entity type as a string. There is an additional parameter,
type, which may take the values "intersect" or
"union". This determines whether fields not present in all
layers will be removed, or retained with NA values for rows
in rezrDFs that don’t have that column.
head(combineLayers(rez007, "chunk", type = "intersect"))
#> # A tibble: 6 × 23
#> id doc name nest kind place text trans…¹ endNote order negPl…²
#> <chr> <chr> <chr> <dbl> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
#> 1 35E3E0AB680… sbc0… Chun… 2 "" "" Stay… Stay u… "" "" ""
#> 2 1F6B5F0B3FF… sbc0… Chun… 3 "" "" the … the pu… "" "" ""
#> 3 24FE2B219BD… sbc0… Chun… 2 "" "" gett… gettin… "" "" ""
#> 4 158B579C1BA… sbc0… Chun… 1 "" "" the … the mo… "" "" ""
#> 5 2F857247FD9… sbc0… Chun… 1 "" "" a ha… a hard… "" "" ""
#> 6 2B6521E8813… sbc0… Chun… 1 "" "" all … all th… "" "" ""
#> # … with 12 more variables: corpusSeq <chr>, pSentOrder <chr>, POS_dft <chr>,
#> # tokenSeq <chr>, chunkType <chr>, turnOrder <chr>, largerChunk <chr>,
#> # tokenOrderFirst <dbl>, docTokenSeqFirst <dbl>, tokenOrderLast <dbl>,
#> # docTokenSeqLast <dbl>, layer <chr>, and abbreviated variable names
#> # ¹transcript, ²negPlace
#> # ℹ Use `colnames()` to see all variable names
#head(combineChunks(rez007, type = "intersect")) #Does the same thingCorrespondence between higher-level and lower-level structures
In the nodeMap, we often see lists of values when a
higher-level structure consists of several elements of a lower
structure, e.g. units contain a list of entries inside it. However,
these lists are all eliminated from rezrDF representations.
Notice the lack of entry lists in the unitDF:
head(rez007$unitDF)
#> # A tibble: 6 × 21
#> id doc unitS…¹ unitEnd unitSeq pID unitId unitS…² docId unitDur pSent…³
#> <chr> <chr> <chr> <chr> <dbl> <lgl> <chr> <chr> <chr> <chr> <chr>
#> 1 2AD1… sbc0… 0.000 12.700 1 NA 1 0.000 sbc0… 12.700 1
#> 2 BDD7… sbc0… 12.640 14.450 2 NA 2 12.640 sbc0… 1.810 1
#> 3 2752… sbc0… 14.450 15.850 3 NA 3 14.450 sbc0… 1.400 2
#> 4 8487… sbc0… 15.850 21.200 4 NA 4 15.850 sbc0… 5.350 3
#> 5 107F… sbc0… 21.200 22.500 5 NA 5 21.200 sbc0… 1.300 4
#> 6 3078… sbc0… 22.500 24.150 6 NA 6 22.500 sbc0… 1.650 5
#> # … with 10 more variables: unitDurSkipPause <chr>, unitEnd.1 <chr>,
#> # unitStartSkipPause <chr>, sequence <chr>, participant <chr>, turnSeq <chr>,
#> # text <chr>, transcript <chr>, docTokenSeqFirst <dbl>,
#> # docTokenSeqLast <dbl>, and abbreviated variable names ¹unitStart,
#> # ²unitStart.1, ³pSentSeq
#> # ℹ Use `colnames()` to see all variable namesThis is for simplicity’s sake. Although it is technically possible to
include these lists in data frames, it is clumsy and will likely slow
down rezonateR a lot to do so.
Of course, understandably sometimes we will still need to refer to
each individual component of a larger entity. The function
getLowerFieldList() is a way, if somewhat clumsy, of doing
this. In this example, we extract the ‘kinds’ (Word, Pause, etc.) of the
tokens of certain units:
getLowerFieldList(rez007,
fieldName = "kind",
simpleDF = rez007$entryDF,
complexDF = rez007$unitDF,
complexNodeMap = rez007$nodeMap$unit,
listName = "entryList",
complexIDs = c("2AD10A854E6D3", "BDD7D839325A", "2752E3B395FC1")
)
#> $`2AD10A854E6D3`
#> [1] "Pause" "Word" "EndNote"
#>
#> $BDD7D839325A
#> [1] "Word" "Word" "Word" "Word" "Word" "Word" "Word"
#> [8] "Word" "Word" "Word" "EndNote"
#>
#> $`2752E3B395FC1`
#> [1] "Pause" "" "Word" "Word" "Word" "EndNote"The arguments to this function are:
fieldNameis the attribute we’re extractingsimpleDFis therezrDFof the ‘smaller’ entitycomplexDFis therezrDFof the ‘larger’ entitycomplexNodeMapis the nodeMap of the ‘larger’ entitylistNameis the name of the list inside each node of thecomplexNodeMapthat gives the lower-level entriescomplexIDsgives the IDs of the ‘larger’ entities (in this case units) you want to extract values for. If left blank, this will be every single complex node (in this case every unit).
This is a very complicated function. One annoying use case is to get
properties of tokens from track entries, so I provide the function
getTrackTokens() to do this easily. For example, this code
extracts the kind value of tracks:
getTrackTokens(rez007, fieldName = "kind", trackDF = rez007$trackDF$default)[1:3]
#> $`1096E4AFFFE65`
#> [1] "Word"
#>
#> $`92F20ACA5F06`
#> [1] "Word"
#>
#> $`1F74D2B049FA4`
#> [1] "Word"In general, though, it is preferable to minimise this type of
extraction. The coming tutorials will explain how we can do common
operations without resorting to using getLowerFieldList();
for example, addFieldForeign() in EasyEdit
(see the EasyEdit
tutorial at vignette("edit_easyEdit")) will allow you
to add a field to the table with the higher-level (e.g. structure that
is created by getting a single summary value of a field in a a
lower-level structure), and rez_left_join() in
TidyRez allows you to perform similar operations with a
tidyverse syntax (see vignette("edit_tidyRez").
Onwards!
Now that you know your way around .rez files and
rezrObjs, you can go to the next tutorial to see how time
is handled in Rezonator. If you’re up for that, go to the tutorial
on time and sequence (vignette("time_seq"))!